
 by lolatanaka17263
by lolatanaka17263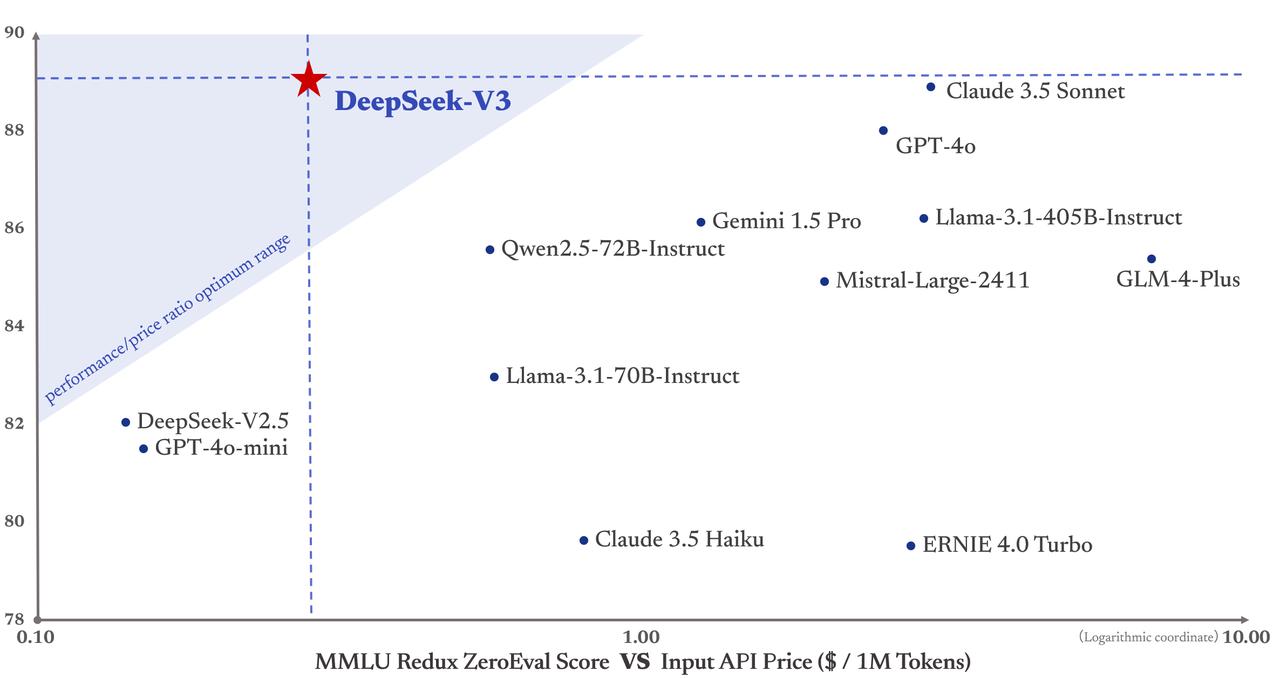 DeepSeek Coder 2 took LLama 3’s throne of price-effectiveness, however Anthropic’s Claude 3.5 Sonnet is equally succesful, much less chatty and far sooner. DeepSeek v2 Coder and Claude 3.5 Sonnet are more value-efficient at code generation than GPT-4o! And even probably the greatest fashions at the moment obtainable, gpt-4o still has a 10% chance of producing non-compiling code. There are solely three fashions (Anthropic Claude three Opus, DeepSeek-v2-Coder, GPT-4o) that had 100% compilable Java code, whereas no mannequin had 100% for Go. deepseek ai, an AI offshoot of Chinese quantitative hedge fund High-Flyer Capital Management focused on releasing excessive-efficiency open-source tech, has unveiled the R1-Lite-Preview, its latest reasoning-centered giant language model (LLM), accessible for now solely by way of DeepSeek Chat, its net-based AI chatbot. This relative openness additionally signifies that researchers world wide are now able to peer beneath the model’s bonnet to search out out what makes it tick, not like OpenAI’s o1 and o3 which are successfully black boxes.
DeepSeek Coder 2 took LLama 3’s throne of price-effectiveness, however Anthropic’s Claude 3.5 Sonnet is equally succesful, much less chatty and far sooner. DeepSeek v2 Coder and Claude 3.5 Sonnet are more value-efficient at code generation than GPT-4o! And even probably the greatest fashions at the moment obtainable, gpt-4o still has a 10% chance of producing non-compiling code. There are solely three fashions (Anthropic Claude three Opus, DeepSeek-v2-Coder, GPT-4o) that had 100% compilable Java code, whereas no mannequin had 100% for Go. deepseek ai, an AI offshoot of Chinese quantitative hedge fund High-Flyer Capital Management focused on releasing excessive-efficiency open-source tech, has unveiled the R1-Lite-Preview, its latest reasoning-centered giant language model (LLM), accessible for now solely by way of DeepSeek Chat, its net-based AI chatbot. This relative openness additionally signifies that researchers world wide are now able to peer beneath the model’s bonnet to search out out what makes it tick, not like OpenAI’s o1 and o3 which are successfully black boxes.
Hemant Mohapatra, a DevTool and Enterprise SaaS VC has perfectly summarised how the GenAI Wave is enjoying out. This creates a baseline for “coding skills” to filter out LLMs that do not assist a specific programming language, framework, or library. Therefore, a key discovering is the important need for an automatic restore logic for each code generation tool primarily based on LLMs. And although we are able to observe stronger performance for Java, over 96% of the evaluated fashions have shown a minimum of an opportunity of producing code that does not compile without additional investigation. Reducing the total checklist of over 180 LLMs to a manageable measurement was achieved by sorting based on scores and then costs. Abstract:The fast development of open-source large language fashions (LLMs) has been truly exceptional. The CodeUpdateArena benchmark represents an vital step ahead in assessing the capabilities of LLMs in the code technology domain, and the insights from this analysis might help drive the event of extra sturdy and adaptable fashions that can keep tempo with the quickly evolving software program landscape. The aim of the evaluation benchmark and the examination of its outcomes is to provide LLM creators a tool to enhance the outcomes of software program improvement tasks in the direction of high quality and to supply LLM customers with a comparability to decide on the fitting mannequin for his or her wants.
Experimentation with multi-alternative questions has proven to enhance benchmark performance, particularly in Chinese a number of-selection benchmarks. DeepSeek-V3 assigns extra coaching tokens to study Chinese knowledge, resulting in exceptional performance on the C-SimpleQA. Chinese company DeepSeek has stormed the market with an AI model that is reportedly as powerful as OpenAI’s ChatGPT at a fraction of the price. In other words, you take a bunch of robots (here, some relatively easy Google bots with a manipulator arm and eyes and mobility) and give them access to a giant model. By claiming that we are witnessing progress toward AGI after only testing on a really slender collection of tasks, we are thus far enormously underestimating the range of tasks it might take to qualify as human-stage. For example, if validating AGI would require testing on one million various duties, perhaps we might set up progress in that course by efficiently testing on, say, a consultant collection of 10,000 different tasks. In distinction, ChatGPT’s expansive training knowledge helps various and creative tasks, including writing and common research.
The company’s R1 and V3 models are each ranked in the top 10 on Chatbot Arena, a efficiency platform hosted by University of California, Berkeley, and the corporate says it’s scoring nearly as effectively or outpacing rival models in mathematical duties, normal knowledge and question-and-reply performance benchmarks. Ultimately, solely an important new fashions, basic fashions and prime-scorers had been kept for the above graph. American tech giants might, ultimately, even profit. U.S. export controls won’t be as effective if China can develop such tech independently. As China continues to dominate global AI growth, DeepSeek exemplifies the nation’s ability to provide slicing-edge platforms that problem conventional methods and inspire innovation worldwide. An X user shared that a question made concerning China was mechanically redacted by the assistant, with a message saying the content was “withdrawn” for safety causes. The “utterly open and unauthenticated” database contained chat histories, person API keys, and different sensitive knowledge. Novikov cautions. This subject has been particularly sensitive ever since Jan. 29, when OpenAI – which trained its fashions on unlicensed, copyrighted knowledge from around the web – made the aforementioned claim that DeepSeek used OpenAI technology to prepare its own fashions with out permission.
Leave a Reply